The iPhone XS & XS Max Review: Unveiling the Silicon Secrets
by Andrei Frumusanu on October 5, 2018 8:00 AM EST- Posted in
- Mobile
- Apple
- Smartphones
- iPhone XS
- iPhone XS Max
The A12 Vortex CPU µarch
When talking about the Vortex microarchitecture, we first need to talk about exactly what kind of frequencies we’re seeing on Apple’s new SoC. Over the last few generations Apple has been steadily raising frequencies of its big cores, all while also raising the microarchitecture’s IPC. I did a quick test of the frequency behaviour of the A12 versus the A11, and came up with the following table:
| Maximum Frequency vs Loaded Threads Per-Core Maximum MHz |
||||||
| Apple A11 | 1 | 2 | 3 | 4 | 5 | 6 |
| Big 1 | 2380 | 2325 | 2083 | 2083 | 2083 | 2083 |
| Big 2 | 2325 | 2083 | 2083 | 2083 | 2083 | |
| Little 1 | 1694 | 1587 | 1587 | 1587 | ||
| Little 2 | 1587 | 1587 | 1587 | |||
| Little 3 | 1587 | 1587 | ||||
| Little 4 | 1587 | |||||
| Apple A12 | 1 | 2 | 3 | 4 | 5 | 6 |
| Big 1 | 2500 | 2380 | 2380 | 2380 | 2380 | 2380 |
| Big 2 | 2380 | 2380 | 2380 | 2380 | 2380 | |
| Little 1 | 1587 | 1562 | 1562 | 1538 | ||
| Little 2 | 1562 | 1562 | 1538 | |||
| Little 3 | 1562 | 1538 | ||||
| Little 4 | 1538 | |||||
Both the A11 and A12’s maximum frequency is actually a single-thread boost clock – 2380MHz for the A11’s Monsoon cores and 2500MHz for the new Vortex cores in the A12. This is just a 5% boost in frequency in ST applications. When adding a second big thread, both the A11 and A12 clock down to respectively 2325 and 2380MHz. It’s when we are also concurrently running threads onto the small cores that things between the two SoCs diverge: while the A11 further clocks down to 2083MHz, the A12 retains the same 2380 until it hits thermal limits and eventually throttles down.
On the small core side of things, the new Tempest cores are actually clocked more conservatively compared to the Mistral predecessors. When the system just had one small core running on the A11, this would boost up to 1694MHz. This behaviour is now gone on the A12, and the clock maximum clock is 1587MHz. The frequency further slightly reduces to down to 1538MHz when there’s four small cores fully loaded.
Much improved memory latency
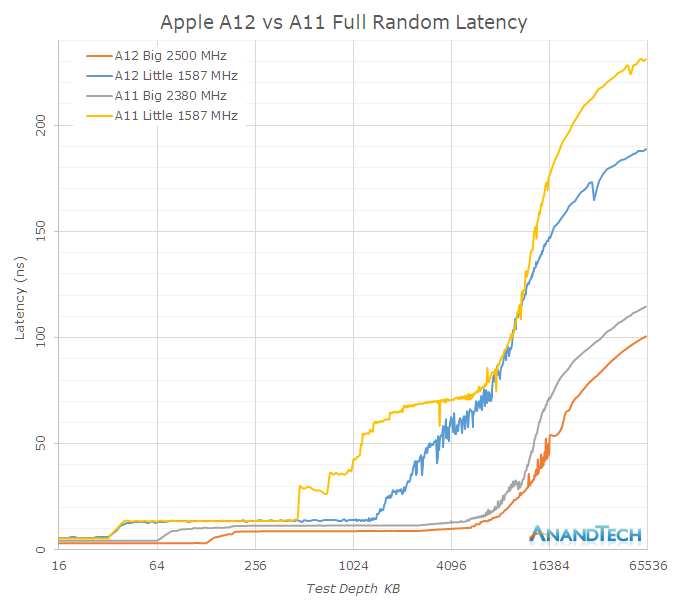
As mentioned in the previous page, it’s evident that Apple has put a significant amount of work into the cache hierarchy as well as memory subsystem of the A12. Going back to a linear latency graph, we see the following behaviours for full random latencies, for both big and small cores:
The Vortex cores have only a 5% boost in frequency over the Monsoon cores, yet the absolute L2 memory latency has improved by 29% from ~11.5ns down to ~8.8ns. Meaning the new Vortex cores’ L2 cache now completes its operations in a significantly fewer number of cycles. On the Tempest side, the L2 cycle latency seems to have remained the same, but again there’s been a large change in terms of the L2 partitioning and power management, allowing access to a larger chunk of the physical L2.
I only had the test depth test up until 64MB and it’s evident that the latency curves don’t flatten out yet in this data set, but it’s visible that latency to DRAM has seen some improvements. The larger difference of the DRAM access of the Tempest cores could be explained by a raising of the maximum memory controller DVFS frequency when just small cores are active – their performance will look better when there’s also a big thread on the big cores running.
The system cache of the A12 has seen some dramatic changes in its behaviour. While bandwidth is this part of the cache hierarchy has seen a reduction compared to the A11, the latency has been much improved. One significant effect here which can be either attributed to the L2 prefetcher, or what I also see a possibility, prefetchers on the system cache side: The latency performance as well as the amount of streaming prefetchers has gone up.
Instruction throughput and latency
| Backend Execution Throughput and Latency | ||||||||
| Cortex-A75 | Cortex-A76 | Exynos-M3 | Monsoon | Vortex | |||||
| Exec | Lat | Exec | Lat | Exec | Lat | Exec | Lat | |
| Integer Arithmetic ADD |
2 | 1 | 3 | 1 | 4 | 1 | 6 | 1 |
| Integer Multiply 32b MUL |
1 | 3 | 1 | 2 | 2 | 3 | 2 | 4 |
| Integer Multiply 64b MUL |
1 | 3 | 1 | 2 | 1 (2x 0.5) |
4 | 2 | 4 |
| Integer Division 32b SDIV |
0.25 | 12 | 0.2 | < 12 | 1/12 - 1 | < 12 | 0.2 | 10 | 8 |
| Integer Division 64b SDIV |
0.25 | 12 | 0.2 | < 12 | 1/21 - 1 | < 21 | 0.2 | 10 | 8 |
| Move MOV |
2 | 1 | 3 | 1 | 3 | 1 | 3 | 1 |
| Shift ops LSL |
2 | 1 | 3 | 1 | 3 | 1 | 6 | 1 |
| Load instructions | 2 | 4 | 2 | 4 | 2 | 4 | 2 | |
| Store instructions | 2 | 1 | 2 | 1 | 1 | 1 | 2 | |
| FP Arithmetic FADD |
2 | 3 | 2 | 2 | 3 | 2 | 3 | 3 |
| FP Multiply FMUL |
2 | 3 | 2 | 3 | 3 | 4 | 3 | 4 |
| Multiply Accumulate MLA |
2 | 5 | 2 | 4 | 3 | 4 | 3 | 4 |
| FP Division (S-form) | 0.2-0.33 | 6-10 | 0.66 | 7 | >0.16 | 12 | 0.5 | 1 | 10 | 8 |
| FP Load | 2 | 5 | 2 | 5 | 2 | 5 | ||
| FP Store | 2 | 1-N | 2 | 2 | 2 | 1 | ||
| Vector Arithmetic | 2 | 3 | 2 | 2 | 3 | 1 | 3 | 2 |
| Vector Multiply | 1 | 4 | 1 | 4 | 1 | 3 | 3 | 3 |
| Vector Multiply Accumulate | 1 | 4 | 1 | 4 | 1 | 3 | 3 | 3 |
| Vector FP Arithmetic | 2 | 3 | 2 | 2 | 3 | 2 | 3 | 3 |
| Vector FP Multiply | 2 | 3 | 2 | 3 | 1 | 3 | 3 | 4 |
| Vector Chained MAC (VMLA) |
2 | 6 | 2 | 5 | 3 | 5 | 3 | 3 |
| Vector FP Fused MAC (VFMA) |
2 | 5 | 2 | 4 | 3 | 4 | 3 | 3 |
To compare the backend characteristics of Vortex, we’ve tested the instruction throughput. The backend performance is determined by the amount of execution units and the latency is dictated by the quality of their design.
The Vortex core looks pretty much the same as the predecessor Monsoon (A11) – with the exception that we’re seemingly looking at new division units, as the execution latency has seen a shaving of 2 cycles both on the integer and FP side. On the FP side the division throughput has seen a doubling.
Monsoon (A11) was a major microarchitectural update in terms of the mid-core and backend. It’s there that Apple had shifted the microarchitecture in Hurricane (A10) from a 6-wide decode from to a 7-wide decode. The most significant change in the backend here was the addition of two integer ALU units, upping them from 4 to 6 units.
Monsoon (A11) and Vortex (A12) are extremely wide machines – with 6 integer execution pipelines among which two are complex units, two load/store units, two branch ports, and three FP/vector pipelines this gives an estimated 13 execution ports, far wider than Arm’s upcoming Cortex A76 and also wider than Samsung’s M3. In fact, assuming we're not looking at an atypical shared port situation, Apple’s microarchitecture seems to far surpass anything else in terms of width, including desktop CPUs.








253 Comments
View All Comments
EnzoFX - Friday, October 5, 2018 - link
I switched. Long time nexus user and I feel Google letting the value orientated base behind. It took me saying screw it and paying more for sure, but it has been worth it. Hardware I found lacking and software too since they went t Pixel. Sure on paper it sounded great or fine, but issue after issue would creep up. I never had that many problems with iOS but I feel it's mature enough coming from someone that likes to change settings. The X sold it for me too hardware wise. It was where I saw things going years ago and glad that it's here. (waiting on the Max now however, as I want the real estate!)RSAUser - Saturday, October 6, 2018 - link
Android just doesn't have direct CPU optimization for latency with scrolling.That said, look at phones with Android 8+, that "issue" is pretty much fixed.
For me, most past iOS7 is not really smooth scroll anymore, was one of the first things I noticed back then. There were dropped frames. You'd probably blame hardware though as it was sorted when upgrading to an iPad Air later. Still not a fan of a lot of the UI changes in 11 tbh
tipoo - Thursday, October 18, 2018 - link
I complained about frame drops from iOS7-11, often to crowds of people who would just deny it and say I was seeing things, but Apple addressed it in a WWDC talk and it's much much better in iOS12.I can still notice a frame drop here and there if I'm being picky, but it's vastly improved, I'm guessing 1 frame drop to every 10 on iOS11.
tipoo - Thursday, October 18, 2018 - link
Since the Pixel 1 it felt pretty well as tight as my iPhone on keeping up with my finger imo (though 120hz touch sensing iPhones may have pulled ahead again).id4andrei - Friday, October 5, 2018 - link
So the A12 is basically a Skylake. Also on Anandtech I read that the first ipad pro was almost a Broadwell(like on the 12" MB). Makes sense. A-series powered macbooks surely are in the future.Color management system is again what puts ios above android. Samsung tries with color profiles but it's not a solution. Google fails its ecosystem yet again. Also OpenCL is a mess, no wonder Apple dropped it. It's unreasonable for you to expect Google to throw its weight around it.
The only thing better than A12 is this review. Absolutely SMASHING review Andrei! Your SoC analysis in particular, off the charts awesome; way more descriptive than lowly Geekbench.
tipoo - Thursday, October 18, 2018 - link
Problem then is Google just has no good GPGPU toolchain if they don't get behind OpenCL. What else is there?They did try Renderscript to limited uptake.
tecsi - Friday, October 5, 2018 - link
Andrei,Great work, and a welcome surprise to see these thorough AnandTech reviews return.
I found the photo and video discussions particularly informative and compelling.
Thanks so much for all your hard work and detailed analysis.
Barry
tecsi - Friday, October 5, 2018 - link
Andrei, could you expand on a few camera issues:- Is it correct that the wider video color range is ONLY at 30fps? Why would this be?
- I have always videoed at 60fps, finding 30fps very noticeable with much movement. If this is correct, it seems like this 30fps color improvement only works in a limited number of situations, with very little movement
- Given the A12 performance, why can’t Apple have 480fps or 960fps SloMo like Samsung?
- Finally, with the Neural Engine, will Apple potentially be able to improve the camera system by re-programming this?
Thanks, Barry
Andrei Frumusanu - Friday, October 5, 2018 - link
> - Is it correct that the wider video color range is ONLY at 30fps?Probably the sensor only works at a certain speed and the HDR works by processing multiple frames. Btw, it's wider dynamic range, not colour range.
> Given the A12 performance, why can’t Apple have 480fps or 960fps SloMo like Samsung?
Likely the sensor might be missing dedicated on-module DRAM - which seems to be a requirement for those high framerates.
> - Finally, with the Neural Engine, will Apple potentially be able to improve the camera system by re-programming this?
They can improve the camera characteristics (choice of exposure, ISO, etc) but I find it unlikely they'll get into things that actively improve image quality - that's something next-gen.
s.yu - Monday, October 8, 2018 - link
The on-module DRAM reduces SNR, AFAIK.